Phonetics vs. Phonology
Today we'll be talking about the sound structure of human language, and the two fields that are dedicated to its study:
- phonetics: the physical manifestation of language in sound waves; how these sounds are articulated and perceived
- phonology: the mental representation of sounds as part of a symbolic cognitive system; how abstract sound categories are manipulated in the processing of language
The sound structure of language encompasses quite a lot of topics, including the following.
- the anatomy, physiology, and acoustics of the human vocal tract;
- the nomenclature for the vocal articulations and sounds used in speech, as represented by the International Phonetic Alphabet;
- hypotheses about the nature of phonological features and their organization into segments, syllables and words;
- the often-extreme changes in the sound of morphemes in different contexts;
- the way that knowledge of language sound structure unfolds as children learn to speak;
- the variation in sound structure across dialects and across time.
Instead of giving a whirlwind tour of the whole of phonetics and phonology, this lecture has two more limited goals. The first goal is to put language sound structure in context.
Why do human languages have a sound structure about which we need to say anything more than that vocal communication is based on noises made with the eating and breathing apparatus?
What are the apparent "design requirements" for this system, and how are they fulfilled?
The second goal is to give you a concrete sense of what the sound systems of languages are like. In order to do this, we will go over examples of sound alternations in various languages. Along the way, a certain amount of the terminology and theory of phonetics and phonology will emerge.
Phonetics: the sounds of language
While our discussion will range back and forth somewhat between the two subdisciplines, we will essentially be progressing from the nuts and bolts mechanics of speech sounds through their classification and representation and on to their systematic organization within a given language. Thus we can divide up the lecture into a more or less phonetic half and a more or less phonological half.
Vocal tract anatomy
The vocal tract is what we use to articulate sounds. It includes the oral cavity (essentially the mouth), the nasal cavity (inside the nose), and the pharyngeal cavity (in the throat, behind the tongue). For most speech sounds, the airstream that passes through this tract is generated by the lungs.
A number of anatomical features of humans that originated for quite different functions have been recruited to serve the purposes of language. Many of these same recruitments have been made by other animals for vocalization.
| Organ | Survival function | Speech function |
| Lungs | exhange oxygen and carbon dioxide | supply airstream |
| Vocal cords | prevent food and liquids from entering the lungs | produce vibration in resonating cavity |
| Tongue | move food within the mouth | articulate sounds |
| Teeth | break up food | provide passive articulator and acoustic baffle |
| Lips | seal oral cavity | articulate sounds |
In some cases the anatomy seems to have evolved specifically to serve language independent (and even contrary to) the original function.
For example, the vocal cords in humans are more muscular and less fatty than in other primates such as chimps and gorillas. This permits greater control over their precise configuration.
Strikingly, the lowering of the larynx, which permits a greater variety of articulations with the tongue, has the consequence of making it much easier for humans to choke. These X-rays and diagrams show the vocal tracts of the gorilla, chimp, and human, highlighting the tongue, larynx, and air sacs (the last for the apes only).
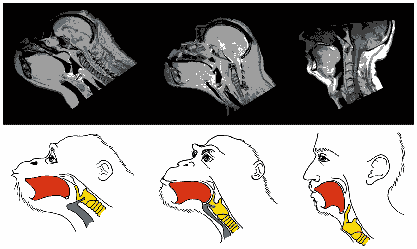
Adapted from W.T. Fitch, The Evolution of Speech
The longer vocal tract (seen behind the tongue in the human) separates the soft palate and epiglottis, so that airflow between the larnyx and the nose cannot avoid passing through the oral cavity. This is why humans choke more easily than other primates. Obviously the selective advantage of increased articulatory ability must have been quite strong to justify the increase in the likelihood of choking. (We'll talk more about this in the last part of the course.)
The following illustration is called a midsagittal section: it's what the head would look like if you cut it in half along the front-back dimension. Don't worry, this is just a plastic model....
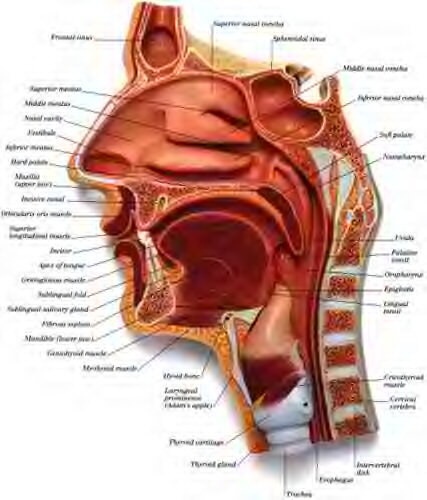
From the Ultimate Visual Dictionary, p. 245
This diagram includes many detailed anatomical features that you certainly don't need to learn, but it should give you an idea of the complex context in which speech sounds are articulated.
Here is a less detailed diagram showing the most important parts of the vocal tract.
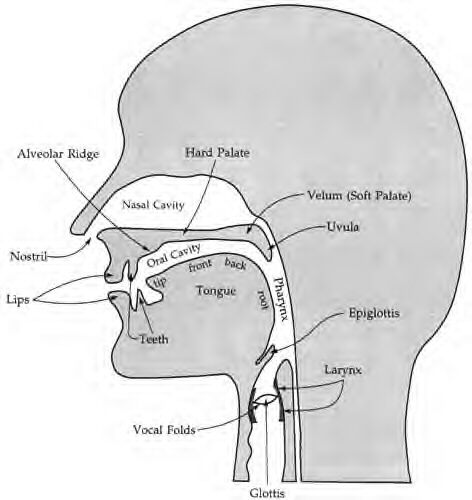
From Language Files (7th ed.), p. 40
We'll be referring to these places in the vocal tract when describing the way various sounds are produced.
Basic sounds: buzz, hiss, and pop
There are three basic modes of sound production in the human vocal tract that play a role in speech: the buzz of vibrating vocal cords, the hiss of air pushed past a constriction, and the pop of a closure released.
Laryngeal buzz
The larynx is a rather complex little structure of cartilage, muscle and connective tissue, sitting on top of the trachea (windpipe). It is what lies behind the "adam's apple," the protrusion in the front of the throat (usually more prominent in males). The original role of the larynx is to seal off the airway, in order to keep food, liquid and other unwanted things out of the lungs, and also to permit the torso to be pressurized (by holding in air) to provide a more rigid framework for heavy lifting and pushing.
Part of the airway-sealing system in the larynx is a pair of muscular flaps, the vocal folds (also called "vocal cords"), which can be brought together to form a seal, or moved apart to permit free motion of air in and out of the lungs.
Here are the vocal cords seen when they are open to allow free passage of air. The front of the body is toward the top of the photo; we're looking down into the dark trachea.
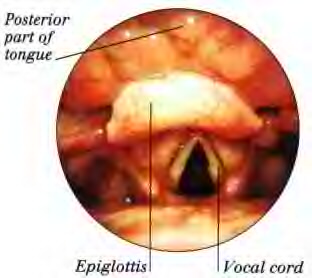
From the Ultimate Visual Dictionary, p. 245
Now for a little aerodynamics. When any elastic seal is not quite strong enough to resist the pressurized air it restricts, the result is an erratic release of the pressure through the seal, creating a sound.
Some homely examples of a similar sound source are the raspberry, where the leaky seal is provided by the lips; the burp, where the opening of the esophagus provides the leaky seal or the fart sounds you can make with your hands under your armpits.
The mechanism of this sound production is very simple and general:
- the air pressure forces an opening, through which air begins to flow;
- the flow of air generates a so-called Bernoulli force at right angles to the flow (which in other circumstances helps airplanes to fly);
- this force combines with the elasticity of the tissue to close the opening again;
- and then the cycle repeats, as air pressure again forces an opening.
In many such sounds, the pattern of opening and closing is irregular, producing a belch-like sound without a clear pitch -- think of the air being released from a balloon.
However, if the circumstances are right, a regular oscillation can be set up, giving a periodic sound that we perceive as having a pitch. Many animals have developed their larynxes so as to be able to produce particularly loud sounds, often with a clear pitch that they are able to vary for expressive purposes.
When the vocal cords are vibrating regularly in this manner, we say that the sound is voiced. Without the vibration, the sound is voiceless (or equivalently, unvoiced). This is exactly the property that distinguishes many sounds in English and other languages. A few examples:
| Voiceless | Voiced |
| s | z |
| f | v |
| p | b |
If you hold your hand to your throat, you will feel vibration for sounds like [z] but not for [s]. You will also feel it for nasals like [m, n] and for vowels like [a]; they are all voiced.
(There is another difference between sounds like [p] and sounds like [b]. The former are accompanied by the puff of breath called aspiration, while the latter are not.)
The hiss of turbulent flow
Another source of sound in the vocal tract -- for humans and for other animals -- is the hiss generated when a volume of air is forced through a passage that is too small to permit it to flow smoothly. The result is turbulence, a complex pattern of swirls and eddies at a wide range of spatial and temporal scales. We hear this turbulent flow as some sort of hiss.
In the vocal tract, this turbulent flow can be created at many points of constrictions. For instance, the upper teeth can be pressed against the lower lip -- if air is forced past this constriction, it makes the sound associated with the letter [f].
When this kind of turbulent flow is used in speech, phoneticians call it frication, and sounds that involve frication are called fricatives. Some English examples are the sounds written "f, v, s, z, sh, th."
The pop of closure and release
When a constriction somewhere in the vocal tract is complete, so that air can't get past it as the speaker continues to breath out, pressure is built up behind the constriction. If the constriction is abruptly released, the sudden release of pressure creates a sort of a pop. When this kind of closure and release is used as a speech sound, phoneticians call it a stop (focusing on the closure) or a plosive (focusing on the release).
As with frication, a plosive constriction can be made anywhere along the vocal tract, from the lips to the larynx. Three common examples:
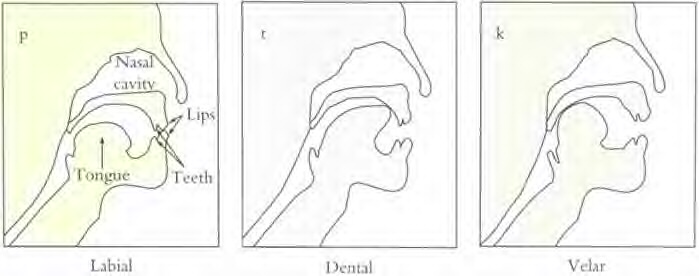
It is difficult to make a firm enough seal in the pharyngeal region to produce a stop, although a narrow fricative constriction in the pharynx is possible.
The phonetic alphabet
The human vocal apparatus can produce a great variety of sounds. As we look at words in other languages -- and study the sounds of English in more detail -- we need a way to write these sounds down. That's what phonetic alphabets are for.
Historical background
In the mid-19th century, Melville Bell invented a writing system that he called "Visible Speech." Bell was a teacher of the deaf, and he intended his writing system to be a teaching and learning tool for helping deaf students learn spoken language. However, Visible Speech was more than a pedagogical tool for deaf education -- it was the first system for notating the sounds of speech independent of the choice of particular language or dialect. This was an extremely important step -- without this step, it is nearly impossible to study the sound systems of human languages in any sort of general way.
In the 1860's, Melville Bell's three sons -- Melville, Edward and Alexander -- went on a lecture tour of Scotland, demonstrating the Visible Speech system to appreciative audiences. In their show, one of the brothers would leave the auditorium, while the others brought volunteers from the audience to perform interesting bits of speech -- words or phrases in a foreign language, or in some non-standard dialect of English. These performances would be notated in Visible Speech on a blackboard on stage.
When the absent brother returned, he would imitate the sounds produced by the volunteers from the audience, solely by reading the Visible Speech notations on the blackboard. In those days before the phonograph, radio or television, this was interesting enough that the Scots were apparently happy to pay money to see it!
There are some interesting connections between the "visible speech" alphabet and the later career of one of the three performers, Alexander Graham Bell, who began following in his father's footsteps as a teacher of the deaf, but then went on to invent the telephone. Look especially at the discussion of Bell's "Ear Phonautograph" and artificial vocal tract.
After Melville Bell's invention, notations like Visible Speech were widely used in teaching students (from the provinces or from foreign countries) how to speak with a standard accent. This was one of the key goals of early phoneticians like Henry Sweet (said to have been the model for Henry Higgins, who teaches Eliza Doolittle to speak "properly" in Shaw's Pygmalion and its musical adaptation My Fair Lady).
The IPA
The International Phonetic Association (IPA) was founded in 1886 in Paris, and has been ever since the official keeper of the Inernational Phonetic Alphabet (also IPA), the modern equivalent of Bell's Visible Speech. Although the IPA's emphasis has shifted in a more descriptive direction, there remains a lively tradition in Great Britain of teaching "received pronunciation" using explicit training in the IPA.
While other phonetic alphabetic notations are in use, the IPA alphabet is the most widely used by linguists.
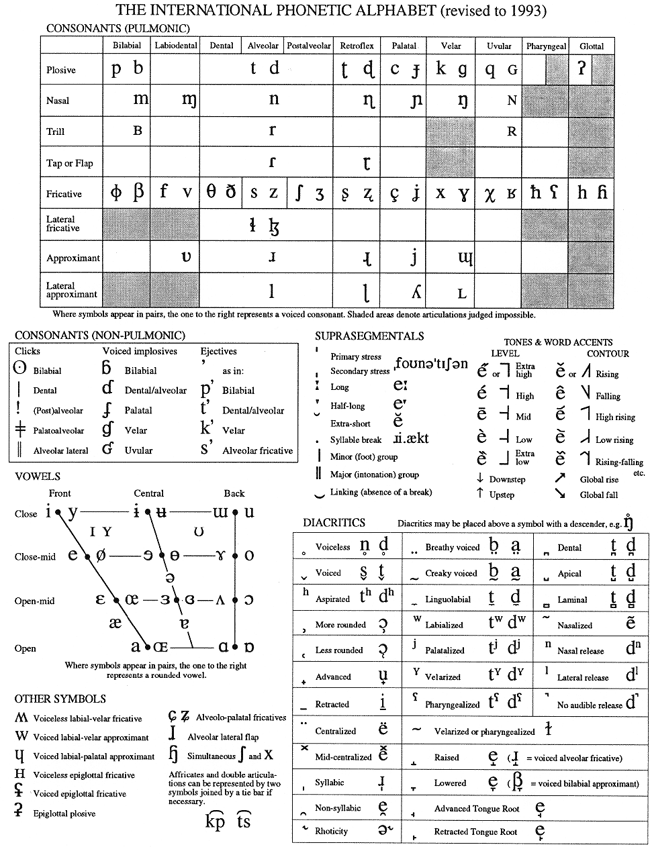
For this course, we'll be using portions of the IPA that describe the sounds of English.
Consonants
We'll begin with a chart of the English consonants. Many of these symbols have their familiar value, but don't confuse spelling with pronunciation. When we write a phonetic transcription, i.e. how a sound or word is pronounced, we'll enclose it in [square brackets] so we know to interpret the symbols in the phonetic alphabet.
Notice that the chart (like the main IPA chart) is organized along two main dimensions. Only terms needed for English are listed here.
- Place of
articulation: where the sound is made
- Bilabial = with the two lips
- Labiodental = with the lower lip and upper teeth
- Interdental = with the tongue between the teeth, or just behind the upper teeth (also called "dental")
- Alveolar = with the tongue tip at the alveolar ridge, behind the teeth
- Palatal = with the front or body of the tongue raised to the palatal region
- Velar = with the back of the tongue raised to the soft palate ("velum")
- Glottal = at the larynx (the glottis is the space between the vocal cords)
- Manner of
articulation: how the tongue, lips, etc. are configured to
produce the sound
- Stop = complete closure, resulting in stoppage of the airflow
- Affricate = closure followed by frication (= stop + fricative)
- Fricative = narrow opening, air forced through
- Nasal = air allowed to pass through the nose (generally while blocked in mouth)
- Liquid = minimal constriction allowing
air to pass freely
- through center of mouth, as in [r], called a rhotic
- around side of tongue, as in [l], called a lateral
- Glide = minimal constriction
corresponding to a vowel (thus also called "semi-vowel")
- [j] corresponds to [i]
- [w] corresponds to [u]
- Flap = the tongue briefly taps the ridge behind the teeth, as in the standard American pronunciation of "tt" in butter
In addition, the obstruent sounds (stops, affricates, fricatives) come in voiced and voiceless varieties. The sonorant sounds (nasals, liquids, glides) are normally voiced.
| Bilabial | Labio- dental |
Inter- dental |
Alveolar | Palatal | Velar | Glottal | ||
|
Stop |
Voiceless |
p | t | k |  | |||
|
|
Voiced |
b | d | g | ||||
|
Affricate |
Voiceless |
|
||||||
|
|
Voiced |
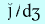 |
||||||
|
Fricative |
Voiceless |
f | θ | s | 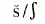 |
h | ||
|
|
Voiced |
v | ð | z | 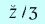 |
|||
|
Nasal |
(Voiced) |
m | n | ŋ | ||||
|
Liquid |
(Voiced) |
l , r | ||||||
|
Glide |
(Voiced) |
w | y/j | |||||
|
Flap |
(Voiced) |
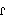 |
The glottal stop, which is written as 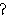 , has a
limited role in English. It is the catch in the throat between the two
vowels in uh-oh.
, has a
limited role in English. It is the catch in the throat between the two
vowels in uh-oh.
The patterning of sounds in languages generally depends on the "natural classes" of sounds defined by these articulatory labels. For example, in English, the plural suffix spelled "(e)s" is realized in three different ways, depending on the preceding sound.
voiceless fricative [s] following another voiceless sound
p, t, k, f, θ
caps, hats, rocks, reefs, birthsvoiced fricative [z] following another voiced sound (including vowels)
b, d, g, v, ð, m, n, ŋ, l, r, w, y
tabs, rods, dogs, caves, lathes, drums, pins, songs, pills, cars, cows, eyesvoiced, but with a vowel inserted before it when it follows a "sibilant", i.e. an alveolar or palatal fricative or affricate.
s, z, č,
, š, ž
kisses, gazes, churches, judges, wishes, rouges
So the rule determining how you pronounce the plural suffix makes reference to the classes voiced, voiceless and sibilant, not to specific sounds like [b], [p] and [s].
Similarly, the past-tense suffix spelled "ed" is realized in three different ways, again depending on the preceding sound.
voiceless stop [t] following another voiceless sound
p, k, f, θ, s, č, š
hopped, kicked, riffed, frothed, kissed, reached, wishedvoiced stop [d] following another voiced sound (including vowels)
b, g, v, ð, z,
robbed, rigged, raved, bathed, razed, raged, rouged, hummed, sinned, longed, filled, marred, plowed, eyedvoiced, but with a vowel inserted before it when it follows an alveolar stop (t or d).
t, d
hated, rented, belted, loaded, grounded, welded
For both suffixes, the inserted vowel serves to separate similar sounds (i.e. it occurs when the stem ends in a consonant similar to the suffixal consonant).
As Pinker discusses, these generalizations can extend to new sounds borrowed from other languages. These German words, which end in voiceless fricatives not found in English (velar and palatal), follow the patterns just discussed when the final consonant is pronounced in the German way.
He out-Bachs Bach with voiceless [s]
She out-Bached Bach with voiceless [t]
The extension of patterns in this way confirms that what speakers understand out these processes is not the arbitrary list of sounds that cause a pattern to arise, but rather the class of sounds -- which could contain members not yet heard in the language.
Vowels
For vowels, a different set of terms is used.
- high-mid-low: height of the tongue in the mouth
- front-central-back: frontness or backness of the tongue in the mouth
- rounded-unrounded: the state of the lips
- in English, as in many languages this is predictable: rounded for high back and mid back vowels, unrounded for other vowels.
- tense-lax : roughly, the degree of tension in the tongue
The terms refer, loosely speaking, to the location of the main tongue constriction within the mouth.
| Front | Central | Back | ||
|
High |
Tense |
i | u | |
|
|
Lax |
I | U | |
|
Mid |
Tense |
e | ə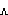 |
o |
|
|
Lax |
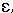 |
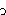 : : | |
|
Low |
(Lax) |
æ | a | |
Most of these symbols are relatively standard, at least to the degree permitted by web-friendly characters; as often in these circumstances, the ə is used for schwa, an upside-down "e" letter.
Here are English words containing the vowel sounds referred to by each of these symbols. These words also exemplify the consonant symbols.
| i | see seat diva |
[si] [sit] [divə] |
| I | sit pin |
[sIt] [pIn] |
| e | say plain take |
[se] [plen] [tek] |
|
let ten |
[lt] [t n]
|
| æ | hat plaid laugh |
[hæt] [plæd] [læf] |
| a | hot papa |
[hat] [papə] |
| : |
saw caught |
[s:] [k :t]
|
| o |
sew |
[so] [rom] [hom] |
| U | put took |
[pUt] [tUk] |
| u | ooze use bloom fume |
[uz] [yuz] [blum] [fyum] |
| ,
while slightly lower, is extremely similar to ə. is
the stressed vowel in "cup", while ə is the unstressed (second)
vowel in "papa". | ||
|
ə |
up sofa attack |
[p] [sofə] [ətæk] |
Many Americans do not distinguish the vowels [a] and [:],
pronouncing cot and caught the same way. That's just one of many variations in pronunciation for different regional
dialects.
In addition to these simple vowels, English has several diphthongs (i.e. vowel sounds that essentially combine a vowel with a glide or semi-vowel in a single unit). These are written, therefore, with two phonetic symbols, even if they can (in the case of "long i") be written with one symbol in English spelling.
| ay | tie sigh my mine |
[tay] [say] [may] [mayn] |
| aw | cow bough cloud |
[kaw] [baw] [klawd] |
| oy | boy coin |
[boy] [koyn] |
(It should be noted here that, in most dialects of English, all of the tense vowels are actually diphthongs. For example, say, which we have represented above as [se] is actually pronounced [sey] by most speakers. However, there is a great deal of variation from dialect to dialect in the specifics of this, and within any given dialect, there is no [e] distinct from [ey], so for our purposes in this course we can stick with the simpler representations like [se].)
Vowel symbols are especially tricky for English speakers, because changes in the history of the language have led to considerable irregularity in the mappings between vowel letters and vowel sounds in English spelling; and the symbols in the phonetic alphabet represent more or less the sounds they represent in most other languages with a Latin-based orthography, but English orthography is very different. If you know some Spanish, German or Italian, for example, you'll be better off thinking of the way vowel sounds are spelled in those languages when you're learning and using the phonetic alphabet.
Transcribing English
There are lots of things to be careful about when doing phonetic transcription. Most important is to pay attention to the sounds, and don't be distracted by the spelling. English spelling is not designed to faithfully represent the sounds of words and is frequently quite misleading in this respect, so it's best to try to ignore it.
For example, a single letter (or combination of letters) "ng" in English spelling can represent two different pronunciations.
- Just a velar nasal [ŋ]
- singer, hangar
- Here "ng" is a digraph, like "ch"
- A velar nasal [ŋ] followed by [g]
- finger, anger
- Here the two letters represent two sounds, like "nk" in thinker
These have to be distinguished in a correct transcription, even though the spellings are the same -- that's a defect of English orthography.
"finger" = [fIŋgr]
"singer" = [sIŋr]
"think" = [θIŋk]
(cf. thin, thing as first part of this word)
Similarly, "th" is ambiguous.
- Voiceless fricative [θ] in thing, ether, thigh
- Voiced fricative [ð] in this, either, thy
And vowels especially are spelled chaotically -- but in phonetic transcription a particular vowel sound is always written the same way. Some examples:
- sound [i]
- spelling fee, tea, be, key, thief, Leigh
- sound [e]
- spelling say, great, made, prey, Mae
- sound [u]
- spelling do, food, new, sue, soup, rude
- diphthong [ay]
- spelling sigh, I, eye, my, hide, lie
- sequence of sounds [si]
- beginning of word: see, sea, senile, seize, scenic, siege, ceiling, cedar, cease
- end of word: juicy, glossy, sexy
The influence of orthography is powerful, even for an International Man of Mystery.
"I put the grrr in swinger, baby!" |
|
|
Mike Myers as Austin
Powers |

Of course, there is no "grrr" in swinger: it's like singer, without a velar stop [g].
[swIhr]
*[swIhgr]
The written "g" is part of a digraph "ng" for the velar nasal that is more properly transcribed [h] in the phonetic alphabet. (One reason to have special symbols like this is to avoid the confusion of things like the "g" in "ng".)
Your pronunciation will differ in some ways from that of your friends or the instructor. This is generally due to difference in regional dialect or sometimes a matter of age.
For example, for a dwindling number of English speakers, the two words in the name of this board game are distinct -- "wh" is voiceless, while plain "w" is voiced. That's a distinction that goes back to Old English and earlier. But for most speakers today (including me), they're homophonous and should both be transcribed with voiced [w].

In homeworks and exams, as long as you give an accurate transcription of how you pronounce something, you'll get full credit. If you think I've taken off credit unfairly for something like this, tell me! I'll ask you to pronounce a word for me, and decide on that basis whether your transcription is in fact a plausible transcription of the way you speak.
Phonology: the structure of sound
Recall the basic distinction mentioned earlier.
- phonetics: the physical manifestation of language in sound waves; how these sounds are articulated and perceived
- phonology: the mental representation of sounds as part of a symbolic cognitive system; how abstract sound categories are manipulated in the processing of language
Thus phonetics refers to the physiological and acoustic parts of the following diagram, while phonology resides in the brain.
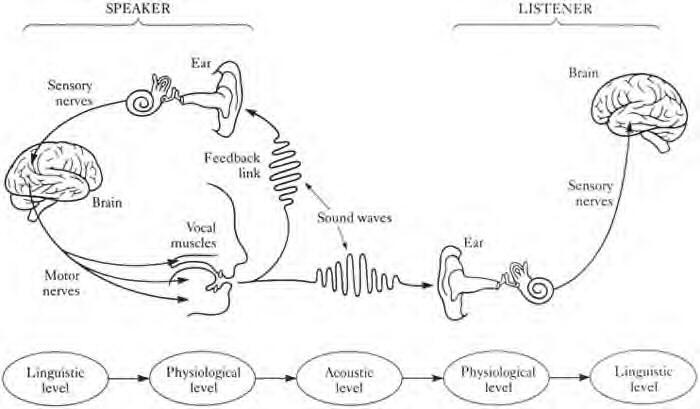
From The Speech Chain
Now we'll focus on the more abstract side of things, and how sounds are organized in a particular language.
Phonemes
The phonological elements of a language are the basic, distinctive sounds, also called phonemes. In English, these are the following (for a dialect of Standard American English).
- consonants: p, t, k, b, d, g, č, , f, θ, s,
š, h, v, ð, z, ž, m, n, ŋ, l, r, w, y
- vowels: i, u, I, U, e, o, , ə, :, æ, a, ay,
aw, oy
These sounds are said to be "distinctive" because they can be used to make contrasts between different words. This can be illustrated for the stops, using minimal pairs (words that differ in exactly one sound).
pill
till
killbill
dill
gill
And for the vowels (We can't get an exact minimal set for the entire range of vowels in the context [h_d], so in some cases the initial consonant also differs. For each individual pair of vowels, however, we could come up with a minimal pair.):
heed
who'd
hid
hood
aid
ode
head
HUD
awed
had
odd
hide
how'd
Boyd
And for the nasals:
rum
run
rung
In English, the velar nasal [h] can't occur at the beginning of a word -- cf. map, nap, *ngap -- which will lead us to the next issue, the way these elements are organized into words.
But first, note that a basic way in which languages differ is their inventory of sounds, or phonemes. For example:
- German has the voiceless velar fricative [x], as in Bach "creek".
- English has voiceless fricatives such as [s] and velars such as [k], but it doesn't have a single phoneme that has both of these properties.
- German also has the high front rounded vowel [ü], as in kühn "clever".
- Again, English has high front [i] and rounded [u], but these properies are not combined in one vowel.
- English [θ] sets it apart
from many languages, including German and French.
- They have several voiceless fricatives, but not the interdental.
When you learn a new language, one of the things you have to do is learn the "list" or inventory of sounds. That's what children have to do also, when learning their native language.
Syllables
The phonological structure of a language -- the way these elements are organized -- includes the notion of syllable and its subparts. This structure is crucially involved in describing the possible words of a language.
- the onset or consonant(s) at the
beginning of the syllable
- English normally permits up to two consonants
- but in addition, [s] can be added to the beginning of many syllables as well, making up to three consonants
- all sounds can occur in this position except for [ŋ]
- the nucleus or vowel that is the
core of the syllable
- sometimes a consonant can serve as the nucleus, as in the second syllable of kitten.
- the coda or consonant(s) at the
end of the syllable
- English normally permits up to two consonants at the end (belt, jump, arc)
- but in addition, certain sounds such as [s, t, θ] can be piled up (belts, sixths)
Here's a general schema of how syllables are constructed.
| SYLLABLE | ||
| ONSET | RHYME | |
| NUCLEUS | CODA | |
| consonant(s) | vowel | consonant(s) |
The category rhyme simply brings together the nucleus and the coda, so the rhyme part of the syllable blend is the nucleus [E] and the coda [nd]. The reason for this name should be obvious: in order for syllables to rhyme, what has to match is just this part of the syllable -- trend, end, spend, etc. (In longer words, rhyme is defined as matching this part of the stressed syllable and all the way to the end of the word: flower, power, shower, tower, hour, scour, etc.)
Sonority
Human speech, like many animal vocalizations, tends to involve repetitive cycles of opening and closing the vocal tract. In human speech, we call these cycles syllables.
A syllable typically begins with the vocal tract in a relatively closed position -- the syllable onset -- and procedes through a relatively open nucleus, then closing again while approaching the coda or the next syllable's onset. The degree of vocal tract openness correlates with the loudness of the sound that can be made.
Speech sounds differ on a scale of sonority, with vowels at one end (the most sonorous end) and obstruents (stops, affricates, fricatives) at the other end. In between are the liquids [l] and [r], and nasal consonants like [m] and [n].
| * | ||||||
| * | * | |||||
| * | * | * | ||||
| * | * | * | * | |||
| vowels | liquids | nasals | obstruents | |||
| (a, i, u...) | (l, r) | (m, n...) | (t, d, f, z) |
Languages tend to arrange their syllables so that the least sonorous sounds are restricted to the margins of the syllable -- the onset in the simplest case -- and the most sonorous sounds occur in the center of the syllable -- most often a vowel.
Here are some typical English syllables that illustrate this pattern.
"soon"
| * | ||||
| * | ||||
| * | * | |||
| * | * | * | ||
| [s] | [u] | [n] |
"blend"
| * | ||||||||
| * | * | |||||||
| * | * | * | ||||||
| * | * | * | * | * | ||||
| [b] | [l] | [] |
[n] | [d] |
And in "pretending" each syllable corresponds to a peak in sonority.
| * | * | * | ||||||||||||||
| * | * | * | * | |||||||||||||
| * | * | * | * | * | * | |||||||||||
| * | * | * | * | * | * | * | * | * | ||||||||
| [p] | [r] | [ə] | [t] | [] |
[n] | [d] | [I] | [ŋ] |
As a consequence of this sonority requirement, an English word such as film is one syllable:
| * | ||||||
| * | * | |||||
| * | * | * | ||||
| * | * | * | * | |||
| [f] | [I] | [l] | [m] |
But if we try to reverse the last two consonants, the hypothetical word fiml comes out as two syllables, since [l] is a new peak, higher in sonority than the preceding nasal. (This new word would end just like pummel.)
| * | ||||||
| * | * | |||||
| * | * | * | ||||
| * | * | * | * | |||
| [f] | [I] | [m] | [l] |
Similarly, if we change the [l] in film to an obstruent such as [z] in hypothetical fizm, once again we end up with a new syllable. (It would rhyme with prism.)
| * | ||||||
| * | ||||||
| * | * | |||||
| * | * | * | * | |||
| [f] | [I] | [z] | [m] |
These syllabifications aren't something we need to learn for each word: they're a general property of the language. That's why we know how these hypothetical words would be pronounced.
In these last two words, the consonant serves as the sonority peak at the end of the word. The consonant is syllabic, serving as the nucleus in the absence of a vowel. English permits nasals and liquids to serve in this way, at least in unstressed syllables.
prism, bottom, sump'm (for "something"), cap'm (for "captain")
hidden, button, kitten, risenbottle, little, towel
swimmer, higher, butter
For [r], the consonant can function as a vowel even in a stressed syllable.
bird, fur, word
In some dialects, such as Standard British, Boston, and Coastal Southern US, any [r] in the rhyme of a syllable (whether nucleus or coda) loses its r-ness and becomes a schwa-like vowel. These are called "r-less" dialects.
Another general property of English is that there are restrictions on what consonants can serve as an onset cluster -- i.e. the string of (two) consonants at the beginning of a syllable. It's not enough for the sonority to increase from the first consonant to the second: it has to increase by two steps.
- actual words with obstruent + liquid (two steps)
- brick, true, free, crab; play, blue, flea, glib
- possible words with obstruent + liquid
- blick, clee
- impossible words with obstruent + nasal (just one step)
- *bnick, *fnee, *gmue, *dmay
- historical loss of initial consonant in obstruent + nasal
(letter now silent)
- knee, knight, gnat, gnaw
This too is part of our general knowledge of the language: we can distinguish blick and *bnick as "possible" and "impossible" even if we've never heard either word before.
But what about words like snow, with an obstruent + nasal onset cluster? You can take any ordinary English onset, and (subject to some restrictions) tack an [s] on the front of it, completely ignoring sonority. This includes clusters of two consonants that obey the general rule; if the first of these is a voiceless stop, [s] can be added to make three consonants.
snow (cf. no)
| * | ||||
| * | ||||
| * | * | |||
| & | * | * | ||
| [s] | [n] | [o] |
stop (cf. top)
| * | ||||||
| * | ||||||
| * | ||||||
| & | * | * | * | |||
| [s] | [t] | [a] | [p] |
spray (cf. pray)
| * | ||||||
| * | * | |||||
| * | * | |||||
| & | * | * | * | |||
| [s] | [p] | [r] | [e] |
This is a special property of [s] and no other obstruent in English. Essentially, it's because [s] is a perceptually salient sound with loud fricative noise: it doesn't depend in the normal way on syllable structure. Many other languages give similar special treatment to [s] and related sounds; in German (and Yiddish), for example, it's the (alveo)palatal fricative, as in Schmutz "dirt."
Once again, syllable structure is a way in which languages differ.
Hawaiian, for example doesn't allow any coda consonants at all, and a maximum of one consonant in the onset. This means that borrowed words get a lot of extra vowels, to create new syllables of the proper type.
ink > 'înika
Norman > NolemanaPolish, on the other hand, allows more consonants at the beginning or end of a word than English does. This is why some Polish names are hard for English speakers to pronounce, such as Gdansk or Zbigniew Brzezinski.
bzdura "nonsense"
babsk "witch"
grzbiet [gzhbyet] "back"
marnotrawstw [-fstf] "of wastes"
A language learner, when exposed to lots of examples of words and syllables in a new language, comes to understand what structures are possible in that language by observing the attested patterns.
Allophones
There are often differences in the way a phoneme is pronounced in a specific context. The variant pronunciations are called allophones ("other sounds").
When it's important to make this difference:
- we'll use [square brackets] to indicate sounds from a phonetic point of view, i.e. focusing on their physical properties and the details of actual pronunciation;
- and we'll use /slashes/ to indicate sounds from a phonological point of view, i.e. as part of an abstract representation independent of potential differences in the way the sound in pronounced in specific contexts.
- In other words, in the ideal case, [ ] = allophone, / / = phoneme.
A classic example of sound alternation in English, which I mentioned in the first lecture, relates to the [s] found at the beginning of a syllable before a voiceless stop.
Although a word like spin is basically pin with [s] added, the /p/ in each case is pronounced differently.
- pin contains an aspirated version of /p/, with a puff of air after the stop is released; this is written [ph]
- spin contains a plain /p/, without a puff of air after the stop; this is written just [p]
The same is true for pairs like pit~spit, pot~spot, pair~spare, etc.
A simple statement of this alternation is as follows:
| the phoneme /p/ becomes: | allophone [p] | immediately following [s] |
| allophone [ph] | at the beginning of the word |
But the same generalization holds not just for /p/ but for the other voiceless stops, /t/ and /k/. Compare these word pairs:
- top~stop, take~stake, tie~sty, etc.
- kin~skin, cope~scope, can~scan, etc.
So more accurately, there's a single general statement that covers all these cases, stated in terms of natural classes.
| voiceless stops are: | unaspirated | immediately following [s] |
| aspirated | at the beginning of the word |
The aspirated and unaspirated versions of the voiceless stops are in complementary distribution: each occurs in its own context, which does not overlap with the contexts of the other.
The rule stated here assumes words of one syllable only. The full statement of where aspiration occurs in English is more complex: voiceless stops are aspirated when they occur syllable-initially and are followed by a stressed vowel (rápid, raphídity); as well as word-initially regardless of stress (photháto). At the beginning of a word, a preceding /s/ prevents the stop from being syllable- or word-initial.
If related words (containing the same morpheme, or meaningful element) have different stresses, then we often find alternations in whether the same underlying sound /t/ is pronounced phonetically as plain [t] etc. or aspirated [th] etc.
| rápid [p] | rapídity [ph] |
| authéntic [t] | authentícity [th] |
| récord [k] | recórd [kh] |
This process is completely unconscious for most speakers, and often quite hard to unlearn.
English speakers who learn a language like French or Spanish, in which all voiceless stops are unaspirated, typically impose aspiration according to their native rule; but that's wrong for these languages, and sounds foreign.
Similarly, a French or Spanish speaker learning English will typically fail to produce aspiration in the right places; this is part of what it means to have a foreign accent.
Aspiration in English is a small example of what phonological knowledge consists of:
- it's learned unconsciously by children imitating (quite accurately!) the details of the language around them
- it's systematic, applying to all words with voiceless stops, not just some random selection
- it's defined in terms of a natural class (here "voiceless stops") rather than some arbitrary set of three consonants
The study of phonology is largely the investigation of alternations like this -- what changes occur, what sounds undergo them, and in what contexts.
Flapping
A prominent feature of American English affects /t/ and /d/, and is called flapping. A flap is a quick motion with the tongue, in this case against the alveolar ridge. It's similar to the /r/ of Spanish in a word like para, although it's a separate phoneme in that language.
All these English words have flaps where "t" or "d" is written in the spelling (in the relevant dialects).
| butter | caddy |
| pretty | buddy |
| little | water |
The proper phonetic symbol for a flap is - it's an
"r" missing the top left serif.
For most speakers, in the right context a sound that is phonologically /t/ will end up sounding phonetically
just like one that is phonologically /d/, since
both become a flap []. Though
/t/ and /d/ are distinguished by voicing, the flap [ ] is voiced.
Thus these words are all homophonous in flapping dialects, i.e. they're pronounced the same.
| latter | ladder |
| matter | madder |
| petal | pedal |
| mettle | meddle |
| betting | bedding |
| outty (belly button) | Audi (car) |
And the answer in this exchange is therefore ambiguous:
-- Do you want the ladder or the chair?
-- Give me the [læ
It's possible for a more emphatic pronunciation such as [læthr] to avoid the ambiguity; but that's not the usual pronunciation.
Of course, /t/ and /d/ don't always end up as flaps. In many contexts they're distinct, as these minimal pairs illustrate.
| hit | hid |
| tin | din |
| tear | dare |
| melting | melding |
| attain | a Dane |
The question, then, is what context causes flapping to occur.
There are two conditions:
- The /t/ or /d/ has to be between vowels
(this includes a syllabic [r] or [l])
- so not in hit, melting
- The following vowel has to be unstressed.
- so not in tin, attain
If you compare the list of homophones (with flapping) vs. minimal pairs (without flapping), you'll see that only the homophones satisfy both these conditions -- and so flapping occurs, which is what makes them homophones.
The same basic word (or word root, or morpheme) will sometimes undergo flapping, sometimes not, as the context changes. This includes adding a vowel:
| sit [t] | sitting, sitter [
] |
| spot [t] | spotty [
] |
| mad [d] | madder, maddest [
] |
| bird [d] | birdy [
] |
As well as moving the stress (primary ´ or secondary `):
| atómic [th] | átom [
] |
| còmputátion [th] | compúter [
] |
| prágmatìsm [th] | pragmátic [
] |
| addíctive [d] | áddict [
] |
| edítion [d] | édit [
] |
(If the /t/ is syllable- or word-initial, then it's also aspirated, as we should expect.)
And when English borrows a new word, the new word is subject to these patterns too, regardless of the exact situation in the original language.
| tofu [th] | (Japanese [t]) |
| tortilla [th], [th] | (Spanish [t], [t]) |
| coyote [kh], [
] |
(Spanish [k], [t]) |
| condor [kh] | (Spanish/Quechua [k]) |
| panache [ph] | (French [p]) |
These facts show that aspiration and flapping are active parts of our knowledge of English; it's not just something we learn about individual words (such as flapped latter), but rather something that we know about the language.
One of the most interesting things about flapping is how it interacts with a process affecting the diphthong /ay/ in many dialects of English. When followed by a voiceless consonant, the diphthong is "raised" so the first part is more like the first vowel of mother than that of father.
regular diphthong at the end of a word, or before a voiced consonant
Ø, b, d, v, z,
tie, jibe, hide, live, rise, oblige, tithe, time, line, tile, tireraised diphthong before a voiceless consonant
p, t, k, f, s
hype, white, bike, life, ice
What is interesing is that this distinction between [ay] and raised [əy] is maintained even when the voicing distinction is eliminated by flapping. Thus if a speaker has raising in write, that pronunciation is maintained in writer, while rider will have [ai] just like ride.
Thus even though flapping eliminates the distinction between the consonants in these two words, they still do nor rhyme.
Most speakers are aware that the two words are pronounced differently, but they think that the difference lies in the consonants. In fact, as far as the actual sounds produced are concerned, the difference lies entirely in the vowels.
The reason why speakers "hear" the difference in the consonants is because, on an abstract level in their minds, the words are represented as /rayter/ and /rayder/, with the difference localized in the consonant. The raising of the /ay/ in the former, and the flapping of the consonants in both are subsequent unconscious processes.
What we must ask ourselves, then, is how raising keeps working properly to distinguish these two words when the conditioning factor on raising -- voicing on the following consonant -- has been obliterated.
We might imagine that speakers raise the /ay/ in writer on analogy to write, where the conditioning factor is still intact. However, this leaves it as mysterious why they treat the two words differently for the purposes of flapping. If phonological rules are simply steered by the properties of the basic root, then we would expect flapping in writer to fail because it fails in write.
Instead, it seems like what is happening is that speakers have an abstract representation of a word in their minds, and they apply phonological rules to these representations in some order, so that the output of one rule can be the input to another:
- writer
/rayter/ --> raising --> /rəyter/ --> flapping --> /rəy
er/
- rider
/rayder/ -->
raising/rayder/ --> flapping --> /rayer/
What does phonology do for us?
So we've gotten an idea now of how the sounds of language are produced, how they are classified, and how they fit together into systems. An interesting question to ask is why it should be as it is. In this last section we will consider this issue and see that the phonology of human language is an ingenious solution to a serious problem.
Apparent design features of human spoken language
We can start by listing a few characteristics of human spoken languages:
- Large vocabulary: 10,000-100,000 items
- Open vocabulary: new items are added easily
- Variation in space and time: different languages and "local accents"
- Messages are typically structured sequences of vocabulary items
- Small vocabulary: ~10 items
- Closed vocabulary: new "names" or similar items are not added
- System is fixed across space and time: widely separated populations use the same signals
- Messages are usually single items, perhaps with repetition
- Vocalizations communicate individual identity
- Vocalizations communicate attitude and emotional state
- Easy naming of new people, groups, places, etc.
- Signs for arbitrarily large inventory of abstract concepts
- Language learning is a large investment in social identity
How can it work?
Experiments on vocabulary sizes at different ages suggest that children must learn an average of more than 10 items per day, day in and day out, over long periods of time.
A sample calculation:
- 40,000 items learned in 10 years
- 10 x 365 = 3,650
- 40,000 / 3,650 = 10.96
Most of this learning is without explicit instruction, just from hearing the words used in meaningful contexts. Usually, a word is learned after hearing only a handful of examples. Experiments have shown that young children can learn a word (and retain it for at least a year) from hearing just one casual use.
Let's put aside the question of how to figure out the meaning of a new word, and focus on how to learn its sound.
You only get to hear the word a few times -- maybe only once. You have to cope with many sources of variation in pronunciation: individual, social and geographical, attitudinal and emotional. Any particular performance of a word simultaneously expresses the word, the identity of the speaker, the speaker's attitude and emotional state, the influence of the performance of adjacent words, and the structure of the message containing the word. Yet you have to tease these factors apart so as to register the sound of the word in a way that will let you produce it yourself, and understand it as spoken by anyone else, in any style or state of mind or context of use.
In subsequent use, you (and those who listen to you speak) need to distinguish this one word accurately from tens of thousands of others.
Note that the perceptual error rate for spoken word identification is less than one percent, where words are chosen at random and spoken by arbitrary and previously-unknown speakers. In more normal and natural contexts, performance is much better.
Let's call this the pronunciation learning problem. If every word were an arbitrary pattern of sound, this problem would probably be impossible to solve.
So what makes it work?
The Phonological Principle
In human spoken languages, the sound of a word is not defined directly (in terms of mouth gestures or acoustic wave patterns). Instead, it is mediated by encoding in terms of a phonological system:
- A word's pronunciation is defined as a structured combination of a
small set of elements
- The available phonological elements and structures are the same for all words (though each word uses only some of them)
- The phonological system is defined in terms of patterns of
mouth gestures and noises
- This "grounding" of the system is called phonetic interpretation
- Phonetic interpretation is the same for all words
How does the phonological principle help solve the pronunciation learning problem? Basically, by splitting it into two problems, each one easier to solve.
- Phonological representations are digital, i.e. made up of discrete
elements in discrete structural relations.
- Copying can be exact: members of a speech community can share identical phonological representations
- Within the performance of a given word on a particular occasion, the (small) amount of information relevant to the identity of the word is clearly defined.
- Phonetic interpretation is general, i.e. independent of word
identity
- Every performance of every word by every member of the speech community helps teach phonetic interpretation, because it applies to the phonological system as a whole, rather than to any particular word.
- Speakers of different dialects will have somewhat different phonetic interpretation of the phonological units, but because they are all dealing with essentially the same units, once you learn the basics of a different dialect's phonetic interpretation, you can learn new words from speakers of that dialect, and interpret them phonetically in your own.
Additional Online resources
These are not a required part of the course materials, but are presented for those students who are interested in further information.
- The Phonological Atlas of North America.
- Web site of the International Phonetic Association.
- On-line spectrogram reading tutorial (a spectrogram is a kind of visual display of the acoustic information in speech).
- An annotated demonstration of vowel synthesis.
- A self-study course at Sterling University on the phonetics and phonology of "received pronunciation" (standard British English).
- Examples of Canadian raising.